
티스토리 뷰
[Kubernetes - Operator] KUDO 정리 (Kubernetes Universal Declarative Operator - Kudobuilder)
ccambo 2020. 12. 21. 17:06What is KUDO (Kubernetes Universal Declarative Operator - Kudobuilder)
정의
- KUDO는 Operator를 위한 Oeprator
- 선언적 접근 방식을 제공해 애플리케이션의 전체 라이프사이클을 커버하는 범용 오퍼레이터
- 대부분의 경우는 YAML 만을 사용할 수 있는 정도로 쉽게 Kubernetes Operator를 만들 수 있는 툴 킷 + 런타임
- 라이프사이클 Operator들 간의 공통화 및 재 사용성
- 복잡한 상태 저장 애플리케이션에 최적화
- Operator 구축시 개발자의 생산성 향상
- 서비스 운영시 운영자의 생산성 향상
- 기본 제공되는 리파지토리의 여러 Operator들 중에서 고르거나 쉽게 커스터마이징이 가능하다.
- 표준화된 방식으로 Operatators가 동작할 수 있도록 한다.
KUDO는 범용적이고 선언적인 접근 방식 (UD - Universal and Declarative)을 취하기 때문에 어떠한 코드를 사용하지 않고 오퍼레이터를 구성할 수 있도록 지원한다.
Developer 측면
- 개념적으로 "runbooks"와 유사하게 Kubernetes 객체들과 "Plans"를 이용해서 라이프사이클 운영 시퀀스에 대한 추상화 제공
- 라이프사이클 작업들 간의 공통성과 재 사용성
- 작업들 간의 코드 중복과 재사용 가능한 Boilerplate 감소
- 사용자 환경에 맞춤화를 위한 기본 Operator의 "Flavor"를 생성하는 매커님즘 제공
- 소프트웨어와 Day 2 운영 모범사례를 제공할 수 있는 도구들을 ISV들에 제공
- Kubernetes 리소스의 TDD 활성화를 위한 테스트 툴 제공
User 측면
- 워크로드들을 배포하고, 관리하고 디버깅할 수 있는
kubectl kudo플러그인 제공 - KUDO는 작은 Kubernetes로
kubectl사용 지원 - KUDO is Kubernets! (단, KUDO 역시 CRD로 정의된 리소스일 뿐) - 클러스터에 다양한 Operator들을 배포하는 것이 일반적이기 때문에, 유사한 API 및 CLI / Workflow 경험을 제공
- 모든 워크로드를 CRD로 관리하여 GitOps 촉진
- 이미 존재하는 Operator들도 KUDO를 통해 관리가 가능하고, CRD, CR 및 기타 Operator들을 파악해서 다른 워크로드들의 일부로 종속성를 지원
- (향후) 엔터프라이즈 워크로드를 위한 중앙 집중식 지원, 메트릭/경고 기능 및 보안과 RBAC 기능을 제공
- 워크로드들을 배포하고, 관리하고 디버깅할 수 있는
When?
kubectl apply -f또는helm install로 애플리케이션의 라이프사이클을 관리하기 힘든 경우에 사용한다.- 상태 저장 서비스를 사용하고 백업/복원과 같은 특정 워크플로우를 자동화해야 하는 경우이거나 스케일 업/다운 시 재 구성이 필요한 일반적인 작업을 수행할 떄 추가적인 로직의 실행이 필요한 경우
- 배포 워크플로우에 순차적인 또는 병렬로 처리할 단계가 존재하는 마이크로 서비스를 관리하는 경우 (예를 들어, 동적으로 구성을 생성하거나 마이그레인션 완료를 대기해야 하는 등의 작업)
- 혼돈 및 탄력성 테스트와 같이 애플리케이션 라이프사이클 전체에 걸쳐 반복적인 작업을 자동화해야할 경우
Concepts
- Operator Package :
Helm Chart 나 Homebrew formula와 같은 KUDO Operator를 정의하는 파일의 모음이며, 로컬 (folder or tarball) 또는 원격 (tarball URL)일 수도 있고, 실행할 애플리케이션에 대한 모든 Kubernetes 리소스 및 워크플로우가 정의되어 있다. - Repository : Operator 패키지를 보관하는 곳으로 로컬 폴더 또는 원격 URL일 수 있다.
- KUDO Manager : KUDO Operator들을 이해하고 Plan들을 어떻게 실행해야 하는지를 알고 있는 Kubernetes Controller 들의 집합이다.
- Plan : Plan은 Operator의 주요 워크플로우 단위로, 정의된 순서에 따라 클러스터에 Kubernetes 리소스를 적용하거나 삭제하는 일련의 단계를 지정한다.
Usage
사용자가 리포지토리에서 Operator Package를 가져와서 KUDO Manager에 제출하면, KUDO Manager는 자동 또는 요구에 따라서 Operator의 Plan들을 실행하게 된다.
- Operator Package :
Operator Plans
Operator는 몇 가지 Plan들로 구성되고 KUDO를 통해 수행될수 있는 구조화된 방법으로 쓰여진 runbook (실행 책자?)로 보면 된다. 각 Plan은 몇 개의 Phase로 이뤄지고 각 Phase에는 몇 개의 Step 들이 존재한다. 모든 Operator들은 클러스터에 애플리케이션을 배포하는 기본 Plan인 Deploy Plan을 포함해야 한다. 복잡한 애플리케이션인 경우는 백업 및 복원 또는 업그레이드 Plan을 정의한다. 각 Plan의 Phase 와 Step은 순차적 또는 병렬로 동작할 수 있으며, 별도로 지정하지 않는 경우라면 기본적으로 순차 처리한다.
다양한 노드 유형 (부트스트랩, 마스터, 에이전트) 들을 순차적으로 처리하는 데이터 서비스의 추상적인 배포 플랜의 예시는 다음과 같다.
plan: deploy phase: bootstrap-node step: start-bootstrap-node phase: master-nodes step: start-master-nodes phase: agent-nodes step: start-agent-nodes phase: deploy-cleanup step: remove-bootstrap-node순차적인 처리의 기준은 앞 phase의 진행이 성공적이어야 다음 phase로 진행되는 방식이다.
Operator Paramters
Operator들은 파라미터를 사용해서 커스터마이징이 가능하다. 이부분이 다른 비슷한 툴들과 다른 점으로 Operator Paramter는 Plan과 연계되어 있기 때문에 파라미터가 변경되면 자동으로 연계된 Plan이 실행된다. 아래의 예는 애플리케이션 노드의 수와 노드 컨테이너가 사용하는 메모리를 나타내는 것이다.
parameters: - name: NODE_COUNT description: "Number of application nodes" default: "3" trigger: "deploy" - name: NODE_MEM_MIB description: "Memory request (in MIB) for node container" default: "4096" trigger: "update"위의 예에서 볼 수 있는 것처럼 각 파라미터는
tigger필드를 가지고 있는데, 이 필드 값을 통해서 파라미터의 값이 변경되었을 때 실행될 Plan을 지정하게 된다. Operator는 실행 중인 애플리케이션의 안전하게 갱신되는 것을 요구하기 때문에 파라미터의 변경에 밀접하게 연계된다. 예를 들어 NODE_COUNT의 변경은 단지 deploy plan을 실행하면 되지만, NODE_MEM_MIB는 canary 또는 blue/green deploy가 실행되어 새 버전을 Rollout 하는 것이 필요하다. 만일 파라미터에 trigger가 지정되지 않으면 기본적인 deploy plan이 실행된다.물론 파라미터와 연계되지 않고도 수동으로 Plan을 동작시킬 수도 있다.
Default Plans
특별한 목적으로 KUDO가 사용하는 세 가지 Plan이 존재하며 다음과 같다.
- deploy : (필수) 기본 배포 Plan으로 위에서 설명한 파라미터에 trigger가 지정되지 않았을 떄 실행되는 기본 Plan 이다.
- upgrade : Operator 자체를 새로운 버전으로 갱신할때 사용하는 Plan으로 이 Plan이 지정되지 않으면 deploy plan이 실행된다.
- cleanup : Operator가 삭제될 때 사용되는 plan으로 Operator가 제거될 때 graceful shutdown이나 사용한 리소스들을 해제할 수 있는 기회가 된다. 추가적인 사항은 Cleanup Plans 참고
Deep dive into the KUDO CRDs
다시 정리하면
KUDO Manager는 Operator들을 처리하고, Plan들을 호출하는 등의 작업을 수행하는 클러스터에 배포된 Kubernetes Controller 세트이며, Kubernetes CDR 들을 활용해서 Kubernetes API를 확장한다.중요한 구성들은 다음과 같다.
- Operator : Operator CRD는 Kubernetes 클러스터에서 실행할 애플리케이션에 대한 High levle의 설명을 포함한다. Operator 자체를 의미하는 것이 아니라 단지 대상이 되는 애플리케이션의 메타 정보를 의미하는 것이고, 특정 plan이나 리소스등은 포함되지 않는다.
클러스터에 여러 버전의 애플리케이션을 설치할 수 있도록 공통된 메타정보를 관리하는 하는 그룹 개념으로 생각하면 된다. - OperatorVersion : 애플리케이션의 특정한 버전을 의미하고, Operator에 의해서 사용되는 Kubernetes 리소스들 (deployments, services, ...) 과 Plans, Parameters 들을 모두 포함하고 있다. 따라서
인스턴스화 되어 애플리케이션으로 동작할 수 있는 클래스처럼 생각하면 된다. - Instance :
OperatorVersion의 실체화되어 배포된 애플리케이션을 의미하고, OperatorVersion을 클래스라고 한다면 실체화된 객체를 의미한다. OperatorVersion에 정의된 기본 값을 재 정의할 수도 있고, 누락된 파라미터 값을 제공해야 한다. 인스턴스의 생성은 대부분의 경우는 Phases, steps에 따라 Kubernetes 리소스들을 렌더링하고 적용하는 deploy plan을 실행하는 것을 의미한다.
정리
- 하나의 Operator는 여러 개의 OperatorVersion을 가질 수 있다. 예를 들어 요구 사항에 따라 여러 팀이 서로 다른 Kafka 버전을 사용하는 것을 생각하면 된다.
- OperatorVersion과 Instance를 분리하는 것은 동일한 클러스터에 동일한 버전의 애플리케이션을 다른 팀들이 각각 사용할 때 유용하다. 예를 들어 동일한 OperatorVersion을 통하지만 별도의 구성이나 확장이 필요한 경우라고 생각하면 된다.
- Operator나 OperatorVersion은 관리자가 설정 및 처리한다. 사용자는 이 부분을 거의 볼 수 없다. Instance부터 사용자가 처리할 수 있으며 많은 CLI 명령들이 존재한다. 예를 들면 Instance를 생성하며 이름을 지정하는 등의 작업이 가능하다.
$ kubectl kudo install kafka --instance dev-kafka
- Operator : Operator CRD는 Kubernetes 클러스터에서 실행할 애플리케이션에 대한 High levle의 설명을 포함한다. Operator 자체를 의미하는 것이 아니라 단지 대상이 되는 애플리케이션의 메타 정보를 의미하는 것이고, 특정 plan이나 리소스등은 포함되지 않는다.
Limitations
- Cross-namespace ownership and cluster-scoped resources
- Instance가 생성한 모든 리소스는 Instance의 소유
- Instance가 삭제되면 연계된 모든 리소스도 삭제
- Operator, OperatorVersion, Instance 모두 namespace 범위로 한정이므로 리소스도 동일한 namespace만 가능
- 다른 여러 namespace에 리소스를 생성하는 것은 불가능
- cluster-scoped 리소스는 생성가능하지만 resourceOwners 팔드가 Instance 참조로 처리되지 않기 때문에 Instance가 삭제될 때 자동으로 삭제되지 않으며, Instance의 Update/Upgrade에서 문제가 발생할 수 있다. 이 부분은 KEP-5 (cluster-Resource-for-crds)를 통해 해결될 가능성이 존재한다.
- Reconciling arbitrary resources
- KUDO는 임의의 사용자 지정 리소스 유형을 조정할 수 없다.
- KUDO Controller가 조정할 수 있는 것은 Operator, OperatorVersion, Instance 등의 Custom Resource들이다.
- KUDO Controller는 다른 임의의 리소스들을 생성하도록 설정된 정해진 Spec에 따르는 Plan을 실행해서 배포될 수 있도록 한다.
- Cross-namespace ownership and cluster-scoped resources
Architecture
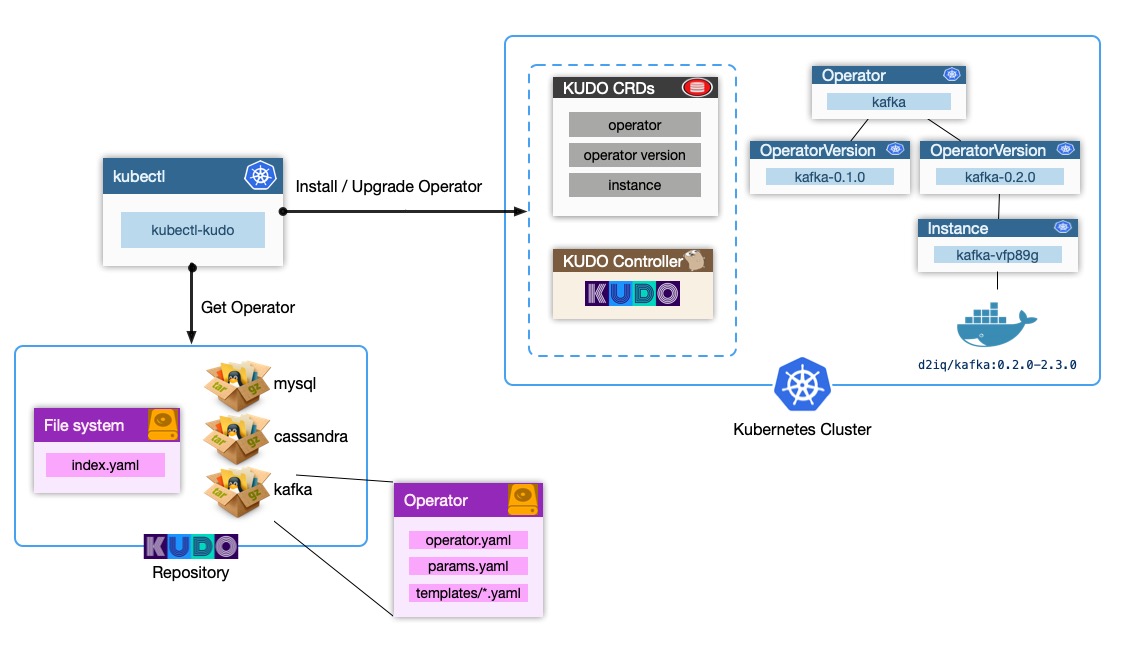
위의 그림과 같이 KUDO CRDs / KUDO Controller 가 설치되어 동작하고 있으며, 실제 Operator에 대한 정보가 KUDO로 전달되면 내부적으로 운영되는 방식이다.
Components
kube-kudo
kubectl 플러그인 명령줄 클라이언트로
kubectl kudo와 같은 방식으로 사용한다. 이 클라이언트는 개발자들이 KUDO Operator 생성을 지원하고, 운영팀이 Kubernetes cluster 내의 Operator들을 관리하는데 사용된다.- Operator 개발
- End to end test harness execution
- Repository 개발 및 관리
- KUDO CRDs를 통해 구현된 KUDO Controller와 상호작용
- Operator CRD들과 Operators 설치와 제거
- Operator Plan의 실행과 상태 조회
- Operator들의 Upgrade / Update, backup / restore
KUDO CRDs
KUDO를 지원할 수 있도록 Kubernetes API 확장
KUDO Controller
클러스터의
kudo-systemnamespace에 배포된 컨트롤러의 모음으로 KUDO CRDs에 정의된 서비스를 제공하고, KUDO Operator들을 관리한다.- Kubernetes의 KUDO Object들을 관찰하고 원하는 상태가 되도록 처리
- KUDO Operator들을 생성하고, Operator의 Plan 호출
KUDO Repository
상당한 편의성을 제공하지만 반드시 필요한 것은 아니며 Operator들이 검색될 수 있도록 URL과 연계된 색인 정보를 제공한다. Operator Repository와 Operator Layout에 대한 자세한 정보는 여기를 참고하도록 한다.
Implementation
- KUDO CLI와 Controller는 Go로 작성되었고, CLI는 Repository와 HTTP 통신을 사용하고 Controller와 통신하기 위해서 Kubernetes client-go를 사용하고 있다.
- KUDO Controller는 를 사용해서 구축되었고, Kubernetes와 통신하는 의존성을 가지고 있다. 모든 KUDO의 상태는 CRD에 저장되기 때문에 별도의 데이터베이스 등은 필요하지 않다.
- KUDO Operator들은 모두 YAML로 작성되었다.
Developing Operators
KUDO의 주요 구성 개념들은 다음과 같다.
- Operator Packages
- Plans
- Tasks
- Parameters
- Templates
간단한 샘플로 만들 Operator는 Nginx를 클러스터에 배치하는 것으로 이 정도로는 KUDO가 필요하지 않다. 단지 KUDO의 강력함 보다는 어떤 과정을 거쳐서 처리하면 되는지를 보여주기 위한 샘플이다.
first-operator라는 이름의 폴더를 하나 생성한다. 이 폴더는 local 패키지를 구성하는 것이다. (이 부분은 뒤에 설명할 Operator Package 단위다)operator.yaml파일을first-operator폴더에 생성하고 아래와 같이 구성한다.apiVersion: kudo.dev/v1beta1 name: "first-operator" operatorVersion: "0.1.0" appVersion: "1.7.9" kubernetesVersion: 1.13.0 maintainers: - name: Your name email: <your@email.com> url: https://kudo.dev tasks: - name: app kind: Apply spec: resources: - deployment.yaml plans: deploy: strategy: serial phases: - name: main strategy: parallel steps: - name: everything tasks: - app위의 내용은
deploy라는 하나의 plan을 가지는 Operator로 하나의 Phase와 하나의 step으로 구성된 최소 설정이다. 이 Operator의 Instance를 클러스터에 배포하면 자동으로 deploy plan이 트리거 된다. step에 지정된 task는app이고 해당 task는 참조하는 리소스로deployment.yaml을 참고하고 있다. KUDO는 이 파일이templates폴더에 존재하는지를 검증한다.deployment.yaml파일을first-operator/templates폴더에 생성하고 아래와 같이 설정한다.apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: {{ .Params.replicas }} # tells deployment to run 2 pods matching the template template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:{{ .AppVersion }} ports: - containerPort: 80위의 파일 내용은 일반적인 Kubernetes의 Deployment를 정의하는 YAML 파일이다. 그러나 잘 보면 KUDO의 템플릿 기능을 사용해서
{{ .Params.replicas }}처리한 것을 볼 수 있다..Params는params.yaml에 정의된 파라미터 정보를 참조하는 것으로 설치를 진행하면서 지정한 파라미터를 정의한 파라미터의 값으로 재 정의해서 처리한다.params.yaml파일을first-operator폴더에 생성하고 아래와 같이 구성한다.apiVersion: kudo.dev/v1beta1 parameters: - name: replicas description: Number of replicas that should be run as part of the deployment default: 2여기까지해서 첫 번째 Operator를 클러스터에 설치할 수 있는 준비를 했다. 아래의 명령을 통해서 실행이 가능하다.
터미널에서 설치 명령 실행
$ kubectl kudo install ./first-operator위의 명령에서
./first-operator값은 실제 Operator Package 폴더를 상대적인 경로를 기준으로 지정하면 된다.이 작업을 위해서는 KUDO CLI 가 설치되어 있어야 한다. 설치를 하면 KUDO에서 사용자의 Operator를 처리하는데 필요로 하는
Operator,OperatorVersion,Instasnce와 같은 다양한 리소스들이 설치된다.클러스터에서 아래와 같이 생성된 정보들을 확인할 수 있다.
# Get instances $ kubectl get instances # or $ kubectl kudo get instances위의 결과가 정상적이라면 아래의 명령으로 pod 정보를 확인할 수 있다.
$ kubectl get pods
이제 KUDO에서 이야기하는 Day 2 Operating에서 Day 1에 해당하는 설치 절차를 확인해 보았다. 실제 설치한 Operator에 대한 테스트는 Test harness document룰 참고하도록 한다.
Operator Package
패키지는 Oeprator를 설명하는데 필요한 모든 파일들을 번들로 처리하며 패키지의 구조는 다음과 같다.
.
├── operator.yaml
├── params.yaml
└── templates
├── deployment.yaml
└── ...- operator.yaml : Operator의 전체 라이프사이클과 메타데이터를 정의하는 메인 YAML 파일이다. Tasks와 Plans는 모두 이 파일에 정의되어 있다. Operator name, version, 유지관리자등의 정보를 제공하는 메타데이터도 여기에 설정된다.
- params.yaml : Opearator에서 사용되는 파라미터들을 정의한다. 설치하는 동안 사용자에 의해서 여기에 정의된 파라미터들은 재 정의될 수 있다.
- templates/ : operator.yaml에 정의된 워크플로우에 기반해서 설치가 된 후 클러스터에 적용할 모든 템플릿화된 Kubernetes objects이 존재한다.
Tasks
Task는 KUDO 워크플로우의 기본적 빌딩 블록이다. Plan, Phases, Steps 는 Task를 실행하는 제어적인 구조들이며, KUDO는 Apply, Delete, Pipe, Toggle, KudoOperator 라는 주요 Task를 제공하고 oeprator를 테스트하고 디버깅하기 위한 Dummy 형식을 제공하고 있다.
모든 Taks들은 operator.yaml 파일에 정의되고 name, kind, spec 의 세 가지 필드를 반드시 포함해야 한다.
tasks:
- name: # Task name defined by the user
kind: # Task kind can be: Apply, Delete, Pipe, Toggle, KudoOperator and Dummy
spec: # Task-specific specificationApply-Task
appy-task는 템플릿을 클러스터에 적용하는 것으로
spec.resources필드는 존재하지 않는다면 생성하고 존재한다면 갱신할 Kubernetes 리소스 리스트 목록을 정의한다.tasks: - name: app kind: Apply spec: resources: - deployment.yamlapp라는 이름의 Task는templates/deployment.yaml에 정의된 리소스의 deployment를 생성한다.KUDO는 정의된 리소스 리스트를 모두 적용하고 모든 리소스가 정상화할 때까지 대기한다. 상태는 특정 리소스마다 달라지며 배포는 Spec으로 정의된 isntance 수가 모두 생성되고 실행되어야 하고 Job은 모두 정상적으로 끝나야 한다.
참고
현재의 구현은 Pod가 미리 생성된 ConfigMap을 마운트할 수 있도록 정의된 순서에 따라서 모든 리소스들을 적용하는 방식이다. 이 부분은 규격의 일부가 아니며 향후 모든 리소스가 동시에 적용될 수 있는 것처럼 변경될 수 있고 리소스간에 순서가 중요한 경우는 순차적인 steps를 사용해야 한다.
apply-task는 KUDO 특정 라벨과 어노테이션을 통해서 배포된 자원을 강화한다. 파드를 셍성하거나 배포하는 리소스 (StatefulSets, Deployments, Daemonsets, ...)의 경우는 KUDO가 pod template spec (ConfigMaps and Secrets)에 의해서 사용되는 모든 리소스들의 hash를 pod template specdp 특정 라벨을 추가한다. 이 해시값의 효과는 ConfigMan을 변경하는 Operator parameter에 대한 갱신으로 해당 ConfigMap을 사용하는 Pod의 재 시작을 호출하게 된다.
Pod는 단지 상위 리소스 (StatefulSet, Deployment)가 적용되는 경우에 재 시작된다. 이런 처리는 동일한 Task의 종속성이나 동일한 plan의 이후 실행되는 Task에 의해서 발생할 수 있다. 즉 ConfigMap만 수정하고 ConfigMap을 사용하는 StatefulSet이 변경되지 않는 경우라면 plan이 실행되도 Pod는 재 시작되지 않는다는 것을 의미한다.
Pod 재 시작을 트리거하는 경우에서 ConfigMap 또는 Secret을 제외하려면 ConfigMap 또는 Secret에 임의 값과
kudo.dev/skip-hash-calculation주석을 추가하면 된다.
Delete Task
apply-task를 사용해서 생성한 리소스들을 삭제하는 Task이다.
tasks: - name: remove kind: Delete spec: resources: - deployment.yaml참고
delete-task는 실제 성공/실패 여부와 상관없이 무조건 성공으로 처리된다. KUDO 0.9.0 에서는 API 서버가 삭제 요청을 받아들이면 실제 리소스가 삭제되는 것을 기다리지 않고 Task를 종료한다. Kubernetest에서는 Pod의 종료에 기본 시간을 30초를 지정해 놓았지만 KUDO 0.9.0 버전에서는 요청이 받아들여지면 처리된 것으로 간주한다.
Toggle-Task
Operator 기능을 개발할 때 리소스를 활성/비활성 처리할 때가 존재한다. toggle-task는 파라미터의 boolean 값을 기준으로 리소스를 적용하거나 삭제한다.
tasks: - name: app-service kind: Toggle spec: parameter: enable-service resources: - service.yaml위 작업은
enable-service파라미터의 값을 기준으로templates/service.yaml에 정의된 리소스를을 적용하거나 삭제하는 것이다. 당연히 사용하는enable-service파라미터는params.yaml에 정의되어 있어야 한다. 만일 없다면 toggle-task는 실패하게 된다.Pipe-Task
복잡한 Operator들을 개발하다보면 종종 한 step에서 파일들을 생성하고 다음 step에서 이를 사용하는 경우가 많다. 일반적인 예는 bootstrap step 에서 사용자 지정 certifications/dynamic 설정 파일을 생성하고, 서비스의 배포 step에서 이를 사용하는 것이다. 이런 상황에서 pipe-task가 도움이 될 수 있다. 예를 들어 index.html를 생성하고 Nginx 서버와 함께 배포할 수도 있다.
tasks: - name: genwww kind: Pipe spec: pod: pipe-pod.yaml pipe: - file: /tmp/index.html kind: ConfigMap key: indexHtmlpipe-task spec은 두 개의 필드를 가진다.
podspec은 index.html을 생성하고 저장할 파일들의 리스트를 정의한다. 생성된 /tmp/index.html 파일은 ConfigMap으로 저장될 것이다. indexHtml 이라는 키로 템플릿 리소스에서 참조가 되며 pipe-task의 spec.pod 는 core/v1 Pod 템플릿을 반드시 참조해야 한다. 그러나 한계가 존재한다. 이에 대해서는 KEP를 참고한다.- pipe-pod.yaml은 initContainer에 파일을 생성한다.
- 파일들이 저장될 emptyDir Volume 하나를 정의하고 마운트해야 한다.
아래는
templates/pipe-pod.yaml이다.apiVersion: v1 kind: Pod spec: volumes: - name: shared-data emptyDir: {} initContainers: - name: init image: busybox command: [ "/bin/sh", "-c" ] args: - wget -O /tmp/index.html 'http://cowsay.morecode.org/say?message=Good+things+come+when+you+least+expect+them&format=html' volumeMounts: - name: shared-data mountPath: /tmp위는 온라인 cowsay-generator API를 이용해서 결과를 /temp/index.html 파일로 다운로드 한다.
위의 pipe-pod.yaml과 genwww task 사양에 따라서 KUDO는 pipe-pod를 실행하고 성공적으로 index.html 파일이 생성될 때까지 기다리고 이를 ConfigMap으로 저장한다. 이 파일은 이제 Nginx 배포 spec에서 사용될 것이다.
... spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 volumeMounts: - name: www mountPath: /usr/share/nginx/html/ volumes: - name: www configMap: name: {{ .Pipes.indexHtml }}ConfigMap으로 부터 마운트 볼륨을 생성했다.
{{ .Pipes.indexHtml } }을 이용해서 ConfigMap 이름을 지정하고,.Pipes키워드는 pipe-artifacts를 처리할 수 있도록 하고, indexHthml은 pipe-task에서 정의한 키다.이제 Task를 기준으로 아래와 같이 deploy plan을 구성할 수 있다.
... plans: deploy: strategy: serial phases: - name: main strategy: serial steps: - name: genfiles tasks: - genwww - name: app tasks: - app위에서
strategy: serial은 순차적 진행으로genfilesstep에서 파일이 생성되기를 기다리고 다음 step에서 이를 사용할 수 있도록 하는 것이다.참고
- 파일을 생성하는 pod는 장애가 발생했을 때 여러 번 실행될 수 있기 때문에 부작용 (side-effect - 타사 API 호출처럼 컨테이너 외부에서 관측할 수 있는 부적용을 의미함)이 없어야 한다.
restartPolicy: OnFailure는 pipe-pod 에 대해서 사용할 수 있다. - 1M 이하의 파일만 ConfigMap이나 Secret으로 저장할 수 있다. 1M 보다 큰 파일은 pipe-task가 실패한다.
- KUDO 0.9.0에서는 pipe-artifacts는 동일한 plan에서만 사용할 수 있다.
- 하나의 pipe-task에서 artifacts를 생성하고 후속 task에서 마운트해서 pipeline 처리를 할 수 있다.
KudoOperator Task
KUDO 0.15.x 기준으로 다른 Opeator들에 대한 종속성을 지정할 수 있는 KudoOperator Task를 지원한다. 종속성은 복잡한 주제지만 KudoOperator 자체는 설치 종속성에 대한 것으로 Operator Instance와 모든 종속성 (전환성 포함)를 하나의 단위로 설치하거나 제거할 수 있게 한다.
KUDO Operators는 Plans, Phases, Steps라고 부르는 설치 의존성을 순차 또는 병렬 수행 전략 기준으로 수행하는 매커니즘을 가지고 있다. 이 매커니즘은 전이적 종속성과 모든 종속성 계층을 표현하기에 이미 충분히 강력하다.
Zookeeper Operator version 0.3.0 (install Zookeeper v3.4.14)에 대한 종속성을 지정하는 간단한 샘플이다.
tasks: - name: deploy-zookeeper kind: KudoOperator spec: package: zookeeper operatorVersion: 0.3.0다른 Task와 마찬가지로 KUDO도 다음 Task로 넘어가기 전에 healty 검증을 한다. 아래의 예는 deploy plan을 사전 준비와 기본인 두 개의 Phase로 구성한 것이다.
plans: deploy: strategy: serial phases: - name: prereqs strategy: parallel steps: - name: first tasks: - deploy-zookeeper - name: main strategy: parallel steps: - name: second tasks: - deploy-main"Healthy"는 이 경우 deploy plan이 COMPLETE 인 것을 의미한다. KudoOperator는 appVersion (최신 버전이 기본 값)과 instanceName (KUDO에 의해서 기본적으로 생성됨)을 추가적으로 지정할 수 있는
kubectl kudo install명령과 의미론적으로 근접하게 모방하는 것이다. 이 명령과 마찬가지로 local operator (또는 원격 tarball)를 Package field로 지정할 수 있다. (e.g package: "./child-operator") 상위 Operator가 설치되는 동안 KUDO CLI는 하위 종속성을 해결하고 Operator 구문 분석과 필요한 리소스를 생성한다.만일 종속성이 local이고 상대 경로 (./child-operator)라면 다음과 같이 처리된다.
- 정의되어 있는 operator.yaml 에 대해 상대 경로로 판단한다.
- kudo install command처럼
./또는../로 접두사를 붙여야 한다.
따라서 다음과 같은 Operator Tree가 지정된다.
. ├── child │ └── operator.yaml │ └── parent └── operator.yamlChild Operator는 parent/operator.yaml에 아래와 같이 상대 경로 지정된다.
- name: child kind: KudoOperator spec: package: "../child"Dependency Parametrization
하위 Operator가 파라미터화 되어야할 필요성이 있다면
parameterFile필드를 사용해서 파라미터 변수 파일을 지정할 수 있다. 예를 들어 상위와 하위 Operator가 있을 때 하위가 빈 값을 기본 값으로 하는 필수 PASSWORD 파라미터가 있다면 상위는 하위를 위해서 파라미터 파일을 지정하고 연관된 KudoOperator에서 참조할 필요가 있다.tasks: - name: deploy-child kind: KudoOperator spec: package: child-operator parameterFile: child-params.yamlchild-params.yaml은 다른 템플릿 파일과 같이 상위 Operator의 템플릿 폴더에 위치한다.# parent/templates/child-params.yaml PASSWORD: {{ .Params.CHILD_PASSWORD }}하위 Oeprator에 전달될
PASSWORD값은 상위 Operator의 파라미터로CHILD_PASSWORD를 이용한다.# parent/params.yaml apiVersion: kudo.dev/v1beta1 parameters: - name: CHILD_PASSWORD displayName: "child password" description: "password for the underlying instance of child operator" required: true따라서 사용자가 상위 Operator를 설치할 떄 평소와 같이 파라미터를 지정하면 된다.
$ kubectl kudo install parent -p CHILD_PASSWORD=secret참고
상위 Operator가 합리적인 기본 값을 제공하거나 사용자에게 노출시키지 않기 위해서 하드 코드로 지정할 수도 있다. 전체적으로 Operator 캡슐화 방법을 제공해서 Operator 구성을 권장한다. 즉 포함된 Operator instance들의 파라미터를 사용자가 임의로 수정하도록 해서는 안된다는 말이다. 상위 Operator는 직접 연결된 하위 Operator가 필요로 하는 모든 파라미터를 정의해야 한다. 자세한 정보는 KEP-29를 참고하면 된다.
Dummy Task
Dummy-Task는 처리가 성공이나 실패할 수 있으며 KUDO Operator 워크플로우를 테스트하거나 디버깅하는데 유용하다.
tasks: - name: breakpoint kind: Dummy spec: wantErr: true # If true, the task will fail with a transient error fatal: true # If true and wantErr: true, the task will fail with a fatal error done: false # if true, the task will succeed immediately이런 task는 Operator 워크플로우에서 중단점으로 유용하고 Operator 개발자가 임의의 step에서 실행을 일시 중지하거나 실패하도록 할 수 있다.
참고
wantErr은done보다 우선한다.- fatal error를 원하는 경우는
wantErr과fatal을 모두 true로 설정해야 한다. wantErr,fatal,doen모두가 false인 경우는 일시 정지한다. (일반적으로 Unhealthy 상태의 자원 시뮬레이션용)
Plans
plan은 운영 과제들 (Tasks)의 개별적인 단계들 (Steps)을 파악하고 이런 업무적인 과제들을 Phases와 Steps 조합으로 구성한다. 각 Step은 실행할 과제들을 참조한다. Task를 Phases 와 Steps 로 정리하면 서비스의 복잡한 행동들을 파악할 수 있다.
Plans 와 Phases 는 전략을 가지고 동작하며 순차적 (Serial)로 동작할지 병렬 (Parallel)로 동작할지를 나타낸다.
...
tasks:
- name: deploy-master
kind: Apply
spec:
resources:
- master-service.yaml
- master.yaml
- name: deploy-agent
kind: Apply
spec:
resources:
- agent-service.yaml
- agent.yaml
plans:
deploy:
strategy: parallel
phases:
- name: deploy-master
strategy: serial
steps:
- name: deploy-master
tasks:
- deploy-master
- name: deploy-agent
strategy: serial
steps:
- name: deploy-agent
tasks:
- deploy-agentKUDO Controller는 Operator에 정의된 Plans 를 배포하며, 한번에 하나의 plan만 배포할 수 있다. KUDO는 어떤 plan을 배포할지를 결정하는 접근 방식이 다르다.
Deploy and update plans
기본적으로 KUDO는 어떤 plan도 배포되지 않은 상황이라면 deploy plan을 시작할 것이다. Instance를 갱신하는 상황이라면 KUDO는 upgrade 또는 update plan이 존재하는지를 검증하고 이를 시작하려고 한다. 만일 해당 plan이 모두 없다면 deploy plan을 시작한다.
아래 예는 service.yaml에 정의된 서비스를 생성하는 deploy plan이다. 갱신 상황이라면 서비스의 캐시를 갱신해야 하는데 update-cache.yaml은 update plan의 일부로 필요한 리소스를 제공한다.
... tasks: - name: app kind: Apply spec: resources: - service.yaml - name: update kind: Apply spec: resources: - service.yaml - update-cache.yaml plans: deploy: strategy: serial phases: - name: deploy-service strategy: serial steps: - name: deploy tasks: - app update: strategy: serial phases: - name: update-service strategy: serial steps: - name: update tasks: - updateCleanup plans
Operator에 옵션이기는 하지만 cleanup plan이 존재한다면 이 plan은 Instance가 삭제될 때 KUDO Manager에 의해서 자동으로 실행되며 이 plan이 성공하던 실패하던 Instance는 삭제된다. 당연히 Instance의 정상적인 라이프사이클 동안에 cleanup plan을 트리거하면 오류가 발생하게 된다. 추가로 이 plan의 step은 실패할 것으로 예상해야 한다. 에를 들어 사용자가 deploy plan이 고착되어 instance를 삭제하길 원하는 상황일 수도 있으며 이런 상황이라면 cleanup plan은 리소스를 삭제하려고 시도하는데 해당 리소스가 클러스터에 존재하지 않을 수도 있기 떄문이다. 따라서 다른 plan이 동작하는 중이라도 cleanup plan은 시작된다.
... tasks: - name: database kind: Apply spec: resources: - database.yaml - name: cleanup kind: Apply spec: resources: - cleanup-job.yaml spec: plans: deploy: strategy: serial phases: - name: deploy-database strategy: serial steps: - name: deploy tasks: - database cleanup: strategy: serial phases: - name: cleanup-databse strategy: serial steps: - name: cleanup tasks: - cleanupInstance가 삭제되면 instance에 속한 모든 리소스가 자동으로 삭제되므로 database.yaml은 삭제할 필요가 없다. 그러나 복잡한 애플리케이션의 경우는 가끔 Kubernetes 리소스로 포착되지 않는 상태를 만들기도 한다. 이런 상황이라면 Operator를 제거할 떄 이 상태를 제거할 수 있으므로 cleanup plan에서 이를 처리할 수 있다. 위의 예제에서는 연계된 Task의 cleanup-job.yaml 에서 필요한 작업을 번들로 묶어서 처리한다. 일반적으로 cleanup plan을 Instance가 삭제되기 전에 호출된다는 점을 제외하면 다른 모든 plan과 동일하다.
cleanup plan은 Finalizers를 사용해서 구현되었고 Instance의
metadata.finalizers에는 cleanup plain이 동작하는 동안 "kudo.dev.instance.cleanup" 값이 설정된다.Parameter Trigger
파라미터는 옵션으로 tigger 속성을 가지고 있고 트리거를 통해서 plan을 지정한다. 따라서 파라미터가 변경되면 지정된 plan이 실행된다.
실행 중인 애플리케이션을 갱신하는데 필요한 작업은 어떤 파라미터가 변경되는지에 따라 달라질 수 있다. 예를 들어 BROKER_COUNT 가 변경되었다면 간단히 배포를 통해서 갱신되는 것이지만, APPLICATION_MEMORY 가 변경되는 경우는 canary 또는 blue/green 배포를 통한 새로운 버전을 Rollout 하는 갱신이 될 수도 있다는 것이다.
... parameters: - name: REPLICAS trigger: deploy - name: APPLICATION_MEMORY trigger: canaryExecuting Plans
KUDO Manager는 파라미터의 변경에 따라 자동적으로 연계된 plan을 실행하지만 가끔 수동으로 plan을 실행시켜야 할 때도 존재한다. 예를 들어 데이터 손상에 대비하기 위해서 주기적으로 백업 plan을 실행해야 하는 경우는 어떤 파라미터가 변경되는 것이 아니기 때문에 수동으로 처리를 해 줘야 한다. KUDO v0.11.0 에서는 이를 위해 수동으로 plan을 호출하는 명령을 제공하고 있다.
$ kubectl kudo plan trigger --name deploy --instance my-instance위의 명령은 deploy plan을 my-instance라는 이름으로 지정된 instance에 대해서 실행하라는 의미다. 단순해 보이지만 실제 구동되는 상황을 잘 살펴봐야 한다.
Plan Life Cycle
필요에 따라서 두 개의 plan이 실행될 수 있다면 (현재는 하나만 실행 가능) 동시에 plan이 동작할 때 어떤 문제가 생길지 생각해 봐야 한다. 만일 plan이 서비스 deploy plan과 monitoring pod를 배포하는 monitoring plan 이라면 서로 연관성이 없어서 병렬로 동작해도 별 문제가 없겠지만, 두 plan이 백업 / 복구 또는 배포 / 마이그레이션 과 같이 연관성이 있는 것이라면 서로 병렬로 동작할 수 없는 상황이며 데이터의 손상을 야기할 수도 있는 문제가 존재한다.
현재는 Plan에 대한 선호도/반선호도, 재선정/비선정, 취소 등 많은 것들을 검토 중에 있다.
Admission Controllers
간단히 보면 Kubernetes admission controller는 클러스터가 어떻게 사용되어야 하는지를 제어하고 실행하는 플러그인으로 인증된 API 요청을 가로채는 GateKeeper로 생각할 수 있으며 요청 객체를 변경하거나 요청을 전면 거부할 수 있다. Kubernetes는 이미 사용자 권한 부여부터 네임스페이스의 수명주기까지 모든 것을 통제하는 등의 사전 설치된 제품을 가지고 있다.
KUDO Manager는 Instance의 변경을 관리하는 Instance admission controller를 사용해서 plan들이 간섭되지 않도록 하고 있다. 아래와 같이 요청은 처리되고 있다.
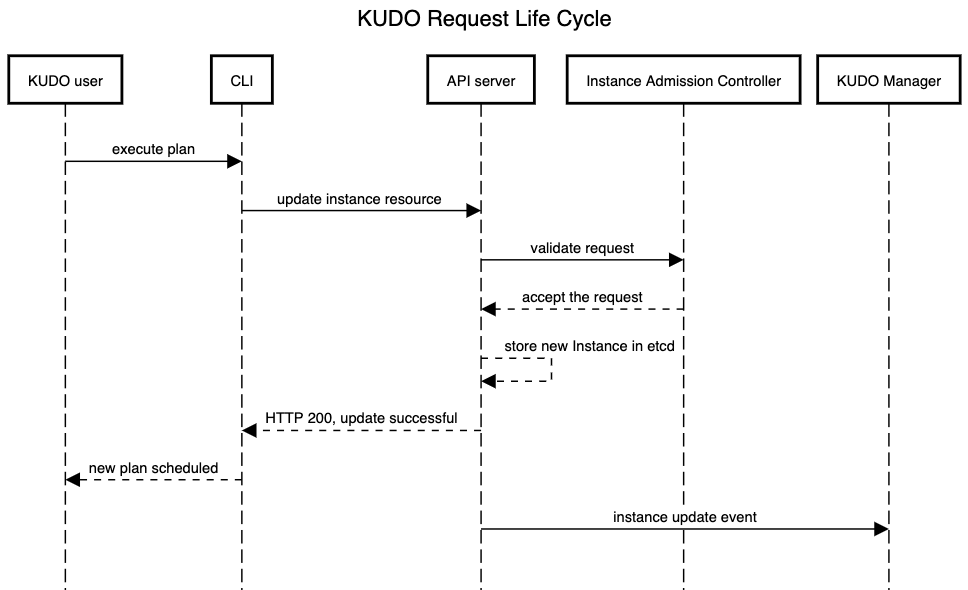
Instance admission controller는 수동으로 실행된 plan 또는 파라미터가 변경되서 실행된 plan을 통해서 instance의 갱신을 모두 관리한다. 일반적으로 새로운 plan이 시작되기 전에 모든 계획은 성공 (COMPLETE)이던 실패 (FATAL_ERROR)이던 종료된 상태여야 한다. 단 하나의 plan만 다시 시작될 수 있고 모든 plan이 재 시작될 수 있을 것으로 간주한다. 요청이 거부되면 instance controller는 명확한 거부 사유를 오류로 반환한다.
또한 파라미터의 변경으로 여러 개별적인 Plan 들이 동작하는 것을 거부한다. 물론 instance가 삭제될 떄 실행되는 cleanup plan은 예외가 된다. 단, cleanup plan은 수동으로 트리거를 할 수 없다.
KUDO 0.11.0의 경우 Instance admission controller는 선택 사항이지만 향후는 의무가 될 예정이다.
Operator Parameters
Operator Parameter는 Operator 개발자가 정의한 key-value 쌍으로 Operator 사용자는 배포할 떄 재정의해서 사용할 수 있으며, 이를 통해서 Operator의 동작을 커스터마이징할 수 있다.
참고
kubectl kudo package list parameters (operatorname)명령을 통해서 Operator에 연관된 모든 파라미터의 리스트를 확인할 수 있다.
Declaring parameters
개발자는
params.yaml파일에 파라미터들은 정의한다. 이 파일은 필수적이고 Operator의 root 디렉터리에 존재해야 한다. 파라미터가 필요없는 경우라면 빈 파일이라도 존재해야 한다.apiVersion: kudo.dev/v1beta1 parameters: - name: BACKUP_FILE description: "Filename to save the backups to." default: "backup.sql" displayName: "BackupFile" - name: PASSWORD default: "password" trigger: backup - name: OPTIONAL_PARAM description: "This parameter is not required." required: False - name: REQUIRED_PARAM description: "This parameter is required but does not have a default value." required: True - name: ARRAY_PARAM description: "This parameter describes an array of values." default: - user1 - user2 type: array - name: MAP_PARAM description: "This parameter describes a map of values." default: label1: foo label2: bar type: map파라미터는 아래와 같은 속성들로 구성된다.
- name : 필수이며 파라미터 이름이다. 대문자로 단어 단위를 '_'로 연결하는 관례를 사용한다.
- displayName : 선택적이며 파라미터의 보여질 이름이다. 다른 곳에는 사용되지 않고 KUDO UI에서 사용된다.
- description : 선택적이며 파라미터의 목적에 대한 설명이다. 다른 곳에는 사용되지 않고 KUDO UI에서 사용된다.
- type : 선택적이며 파라미터 값의 형식을 지정한다. 기본 값은 string 이고, array, map 등도 가능하며 이 경우는 YAML 포맷에 맞도록 값을 지정해야 한다.
- default : 선택적이며 파라미터의 기본 값을 지정한다. 이 속성을 생략하면 해당 파라미터는 required로 설정된다. 이를 변경하려면 required 속성 값을 지정해야 한다.
- required : 선택적이며 설치 시에 파라미터가 반드시 제공되어야 하는지 여부로 true로 설정되어 있는데 설치 시에 제공되지 않으면 설치가 실패하게 된다.
- tigger : 선택적이며 초기 설치 이후에 파라미터의 변경에 따라서 트리거될 Plan을 설정한다. 만일 지정하지 않는다면
update나deployplan이 실행된다. - immutable : 선택적이며 기본 값은 false로 Instance에 대한 갱신할 떄 변경이 가능하지를 나타내는 것이다. 만일 true로 설정된다면 반드시 required 또는 default 값을 가져야 하며 Instance가 설치될 떄 파라마터 값을 설정해야 하며, 나중에는 변경할 수 없는 상태가 된다.
Overriding parameters
Operator 사용자가 CLI를 통해서 파라미터를 재 정의할 수 있다.
kubectl kudo명령에서install, upgrade, update등의 명령을 수행할 때--parameter 또는 -p플래그를 사용해서 처리한다. 지정하는 파라미터는PARMATER_NAME=parameter_value형식으로 처리하고 Array의 경우는PARAMTER_NAME=[array_value1, array_value2]로 처리하고 Map의 경우는PARAMTER_NAME={map_key1:map_value1, map_key2:map_value2}와 같이 처리한다.이 플래그는 여러 파라미터를 지정할 수 있도록 여러 번 사용할 수 있다.
Tiggers
Operator 개발자가 update때 파라미터가 변경되면 실행될 plan의 이름을 지정할 수 있다. 달리 말하면 이 plan이 파라미터의 변경된 값을 Kubernetes 애플리케이션에 적용한다는 의미가 된다. 이를 지정하지 않으면 기본적으로 update plan을 호출하고 이 plan이 없다면 deploy plan을 호출하게 된다.
단, 현재 하나 이상의 plan을 트리거하도록 파라미터를 설정할 수는 없다.
Immutability
Operator는 종종 설치 시점에 설정한 파라미터를 나중에 바꿀 수 없도록 하는 경우가 존재한다. 에를 들어 KUDO Cassandra Operator는 NUM_TOKENS라는 관리되는 클러스터의 각 노드들이 관리할 토큰의 갯수를 지정하는 파라미터를 가지고 있는데, 이 파라미터의 값은 설치할 때 적용되면 Cassandra Cluster의 라이프사이클 동안 변경할 수 없고, 이 값을 변경해야 하는 경우라면 다른 파리미터의 값으로 새로운 Cluster를 구성하고 데이터를 마이그레이션 해야 한다.
이런 불변 파라미터는 기본 값을 가지거나 required로 설정되어야 한다. 즉 설치 시점에 반드시 값이 필요하다는 것이다.
보다 자세한 사항은 KEP-30를 참고한다.
Templates
KUDO는 GO 템플릿 엔진을 사용하고 스플릭 템플릿 기능을 사용할 수도 있다. 이를 통해서 사용자가 파라미터 처리된 Operator 기능을 사용할 수 있도록 하며, Operator Package의 templates 디렉터리에 있는 모든 파일에 적용되어 있다.
Vaiables
{{.Variable}}형식으로 변수의 값을 적용할 수 있다.- .Params :
params.yaml에 정의된 instance parameter에 접근할 수 있다. 예를 들어REPLICAS파라미터를 사용할 경우는{{.Params.REPLICAS}}와 같이 사용한다. - .OperatorName : Operator 명
- .Name : 현재 Instance 명
- .Namespace : Instance가 속한 namespace 명
- .Pipes : Pipeline Parameter
- .PlanName : Instance의 활성화된 Plan 명
- .PhaseName : Instance의 활성화된 Plan의 활성화된 Phase 명
- .StepName : Instance의 활성화된 Plan의 활성화된 Phase의 활성화된 Step 명
- .AppVersion : 애플리케이션의 버전 정보
- .Params :
Functions
입력 값을 변수처럼 변환하고, Pipeline을 이용하면 다른 함수의 결과를 다른 함수의 입력으로 사용할 수도 있다. 이 함수 기능은 Go 템플릿과 Sprig 템플릿에서 제공된다.
Go Template
- Compare :
eq,not,ne,lt, ... 등과 같이 Go Template의 비교 연산자 사용 가능 - Simple Calculate :
len,and,or,add,mul, ... 등과 같은 단순 연산 함수 사용 가능 - Text manipulation :
html,js,trim,wrap, ... 등과 같은 문자열 처리 함수 사용 가능
- Compare :
Sprig Template : 환경 접근을 허용하는 Sprig 함수들은 비활성화된다.
env,expandenv,base,dir,clean,ext,isAbs, ...KUDO Provide
- toYAML : 아규먼트들을 YAML로 반환하며, | trim | indent N 등과 같이 사용한다.
Actions
Action은 템플릿에서 분기 또는 반복 처리에 사용한다. 아래의 내용은 몇 가지 예시로 보다 자세한 사항은 Go Template Actions를 참고한다.
Perform arithmetic using parameters
모든 .Params는 문자열 형식이기 떄문에 처리하기 전에 형식 변환을 먼저해야 한다. 아래의 예는 파라미터에서 1을 뺴는 것이다.
{{ sub (atoi .Params.NODE_COUNT) 1 }}Enable or disable features using a feature parameter
.Params.ENCRYPTION 파라미터가 true/false인지에 따라서 HTTP/HTTPS로 설정한다.
spec: ports: {{ if eq .Params.ENCRYPTION "true" }} - name: https port: 443 {{ else }} - name: http port: 80 {{ end }} ...Create objects for a specific number
.Params.VOLUMES 에 따라서 persistent volume claims를 생성한다.
{{ range $i, $v := until (int .Params.VOLUMES) }} --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: claim-{{ $i }} ... {{ end }}
Limitations
일부 Kubernetes Object들은 템플릿으로 사용할 수 없다. 대표적인 예가 Jobs로
spec.template필드는 변경할 수 없으며, Job이 적용된 후에는 이 필드롤 변경할 수 없다. spec.template를 템플릿화된 파라미터로 변경을 시도하면 아래와 같은 오류가 발생된다.... failed to execute patch: Job.batch "xxx" is invalid: spec.template: Invalid value: core.PodTemplateSpec{...} field is immutable이런 문제는 해당 Job을 삭제 (Delete Task 사용)하고 다시 생성해야 하며, 이 작업은 Operator Developer의 선택이다.
CLI Usage
Concepts
Operator
- High level description of a deployable service
- A deployable service can be anyting that you'd want to run on your cluster
- Represented as a CRD Object
- 여러 개의 OperatorVersion 정보를 가질 수 있다.
OperatorVersion
- Implementation of an Operator
- Specific version of a deployable application
- Contains parameters, objects, plans
- 여러 개의 Instance 정보를 가질 수 있다.
Instance
- Tiles application instantiation to an OperatorVersion
- Once created, renders parameters in templates such as services, pods or StatefulSets
- Can create multiple instances of an OperatorVersion within your cluster
Plan
Orchestarate tasks through phases and steps
A structured 'runbook' which can then be executed by software
Typically define several plans:
- Deploy
- Backup
- Restore
- Upgrade
Phases and steps can be run serial or parallel
CLI
- CLI extension to kubectl
- Can still use 'vanilla' kubectl
Roadmap
Dynamic CRDs : Manage the lifecycle of operator CRDs for the operator developers and users
Operator Dependencies : Ability for KUDO to support a wide range of dependencies (from existing instances and connection strings to entirely new dependencies that are KUDO managed), and for tighter control of dependency specification by operator developers
Operator Extensions : Extend from other formats such as other KUDO operators, Helm charts, or CNAB bundles without forking and operator
Something other than YAML! : Starlark or CUE like candidates
Pipe Tasks
- Generation of content which can then be 'piped' to another task
- e.g certicate generation / creation as part of bootstrap
- Just landed (https://github.com/kudobuilder/kudo/pull/1105)
Helm chart
- Import and extend
Operator Development
Skeleton Generator
Linter
Snippet / extension library
KUDO API
Operator Extensions
KUDO는 Dev/Ops 팀이 Operator 관리를 통해서 상태 저장 서비스를 포함해서 Kubernetes 환경에서 Day 2 Operating 관리를 할 수 있도록 설계되어 초기 배포 이상의 지원 (백업, 복구, 관찰, 업그레이드 등) 한다. 실제 발생하는 사례는 다음과 같다.
참고 자료
'개발 > Kubernetes 이해' 카테고리의 다른 글
| [Kubernetes - Operator] Kubernetes 상의 Operator Tools 간략 비교 (0) | 2020.12.21 |
|---|---|
| [Kubernetes - Operator] Kubernetes상의 Operator 나름대로 정리 (8) | 2020.12.21 |
| [Kubernetes - Operator] KUDO CLI 명령어 정리 (0) | 2020.12.21 |
| [Kubernetes] Kubernetes Dashboard 설치 및 NodePort 접근설정 (0) | 2020.12.19 |
| [Kubernetes - KREW] KREW란 무엇일까? (0) | 2020.12.16 |
- Total
- Today
- Yesterday
- docker
- Kudo
- macos
- KUBECTL
- ssh
- Galera Cluster
- custom resource
- Node
- zookeeper
- GIT
- CentOS 8
- leader
- collection
- provisioner
- Packages
- k8s
- operator
- Cluster
- operator framework
- kudo-cli
- opencensus
- dynamic nfs client provisioner
- Kubernetes
- CentOS
- galera
- 쿠버네티스
- terrminating
- Replica
- SolrCloud
- NFS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |